

Sabemos que alguns caracteres não podem ser exibidos ou usados em alguns ambientes.
Por exemplo, caracteres como &, = são reservados como caracteres com funções especiais em URLs, como descrever uma imagem e se o código binário na imagem for convertido no correspondente caractere, haverá muitos caracteres invisíveis e caracteres de controle (como avanço de linha, retorno de ponteiro, etc.) que são precisos codificá-los para a transferencia via rede sem perdas.
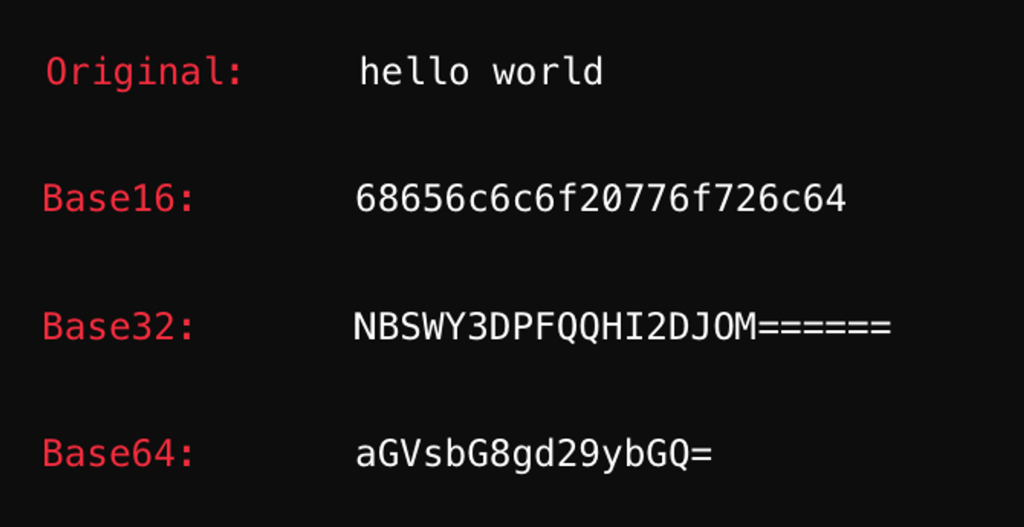
Os algoritmos Base são usados principalmente para a representação correta na transferencia de bytes na internet, codificando esses bytes em caracteres ASCII.
Esse tipo de algoritmo não é utilizado para criptografia, mas sim para codificação.
Nunca deve-se utilizar esse tipo de algoritmo para guardar uma senha, ou transferir dados de forma segura.
Claro, se você quiser embaralhar os caracteres utilizados na sequência de codificação, é outra história, porem você terá que lembrar a sequência de caracteres utilizado no embaralhamento para desembaralhar o conteúdo.
Base32
A codificação Base32 segmenta os dados em grupos de 5 bytes.
Cada grupo de 5 bytes é então convertido em 8 caracteres.
Se um grupo não contiver bytes suficientes, zeros são adicionados após o último byte para completar o grupo de 5 bytes, e o sinal = é usado para preencher até atingir 8 caracteres.
Por exemplo, para codificar uma seção de 5 bytes, esses bytes são divididos e reorganizados para formar 8 caracteres. Se forem codificados 6 bytes, após a primeira reorganização que gera 8 caracteres, a segunda reorganização exigirá a adição de dois zeros e seis sinais de igual (=), resultando em uma sequência do tipo xxxxx xxx00 ====== para completar os 8 caracteres necessários.
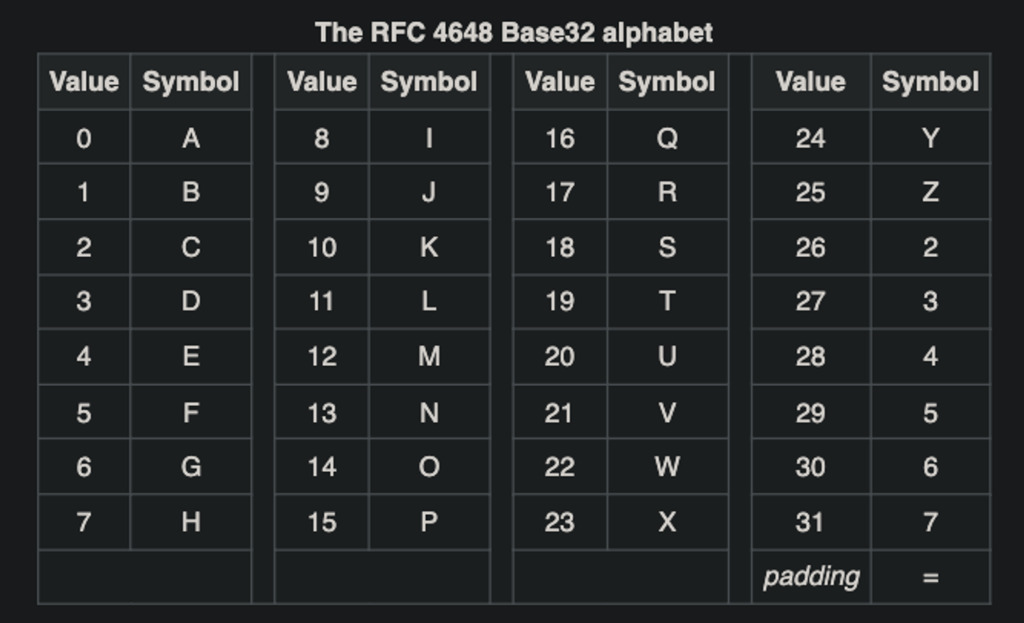
A codificação Base32 utiliza 32 caracteres distintos, aumentando a quantidade de dados em uma proporção de 8/5. Conforme o texto codificado se alonga, o impacto dos dados adicionais (zeros e sinais de =) no final se torna praticamente insignificante.
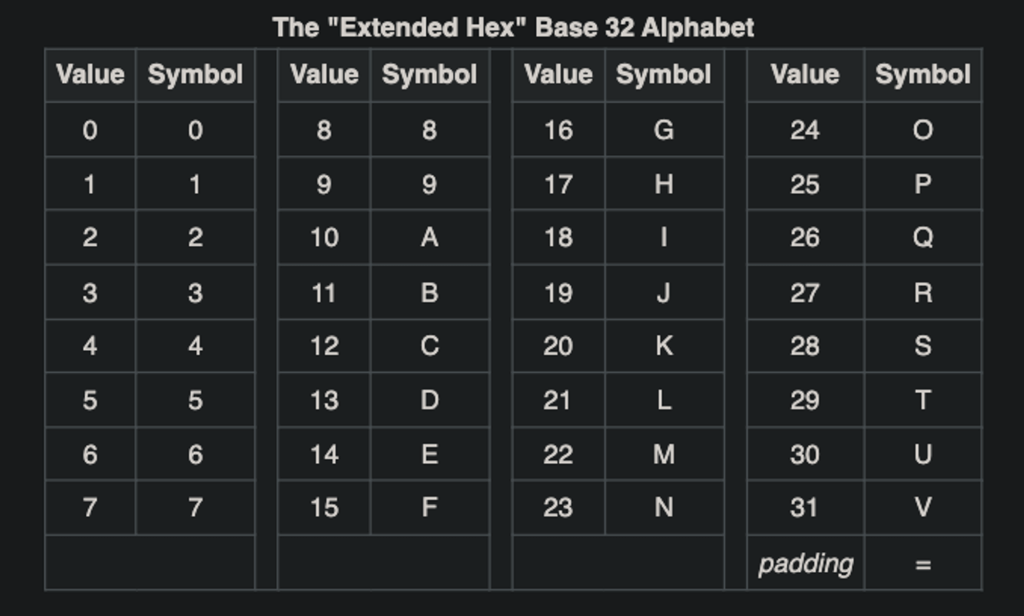
Além do esquema principal de codificação, o base32 têm formas alternativas de dicionário, como o z-base-32, Crockford’s Base32, Electrologica, Geohash, Word-safe.
Existem dois esquemas principais para a codificação de caracteres em Base32: o esquema alfabético e o esquema alfabético hexadecimal estendido.
Base16
A codificação Base16, também conhecida como codificação hexadecimal, divide os dados em bytes individuais.
Cada byte é então representado por dois caracteres hexadecimais. Isso significa que cada dígito hexadecimal pode representar 4 bits, portanto, um byte (8 bits) é codificado como dois dígitos hexadecimais.
Por exemplo, o byte com o valor decimal 255 é representado em hexadecimal como FF. Assim, na codificação Base16, cada byte de dados é convertido diretamente em dois caracteres hexadecimais.
Essa relação direta de 1 byte para 2 caracteres resulta em uma expansão de dados na proporção de 2/1, ou seja, o tamanho do dado codificado é exatamente o dobro do dado original.
A codificação Base16 utiliza 16 caracteres distintos, que são os dígitos de 0-9 e as letras de A-F.
Não há uso de caracteres adicionais como padding ao final dos dados, pois a conversão de cada byte é completa com dois dígitos hexadecimais.
Em resumo, a codificação Base16 é direta e não incorpora complexidades adicionais como preenchimento ou expansão significativa além do dobro do tamanho do dado original.



Seja o primeiro a comentar